EVMbench: Benchmarking AI for Smart Contract Security
OpenAI

¿No sabes por dónde empezar con la IA?Evalúa preparación, riesgos y prioridades en menos de una hora.
➔ Descarga nuestro paquete gratuito de preparación para IA
EVMbench is an open benchmark from OpenAI and Paradigm that evaluates AI agents on smart contract security. It measures three capabilities—detecting vulnerabilities, patching them without breaking functionality, and exploiting them in a controlled environment—so researchers and security teams can track progress, identify failure modes, and improve defensive tooling.
Smart contract failures are unforgiving. When a contract holds real value, a single flaw can be exploited in minutes, with consequences that are difficult—or impossible—to reverse.
As AI agents become more capable at reading, writing and running code, it’s natural for organisations to ask two uncomfortable questions at once:
Can AI help us find and fix vulnerabilities faster?
Could the same capability increase risk if used offensively?
In February 2026, OpenAI and Paradigm introduced EVMbench to help answer both. EVMbench is a benchmark designed to evaluate AI agents’ ability to detect, patch, and exploit high-severity vulnerabilities in smart contracts, using realistic setups that reflect how code behaves on an Ethereum-style chain.
What is EVMbench?
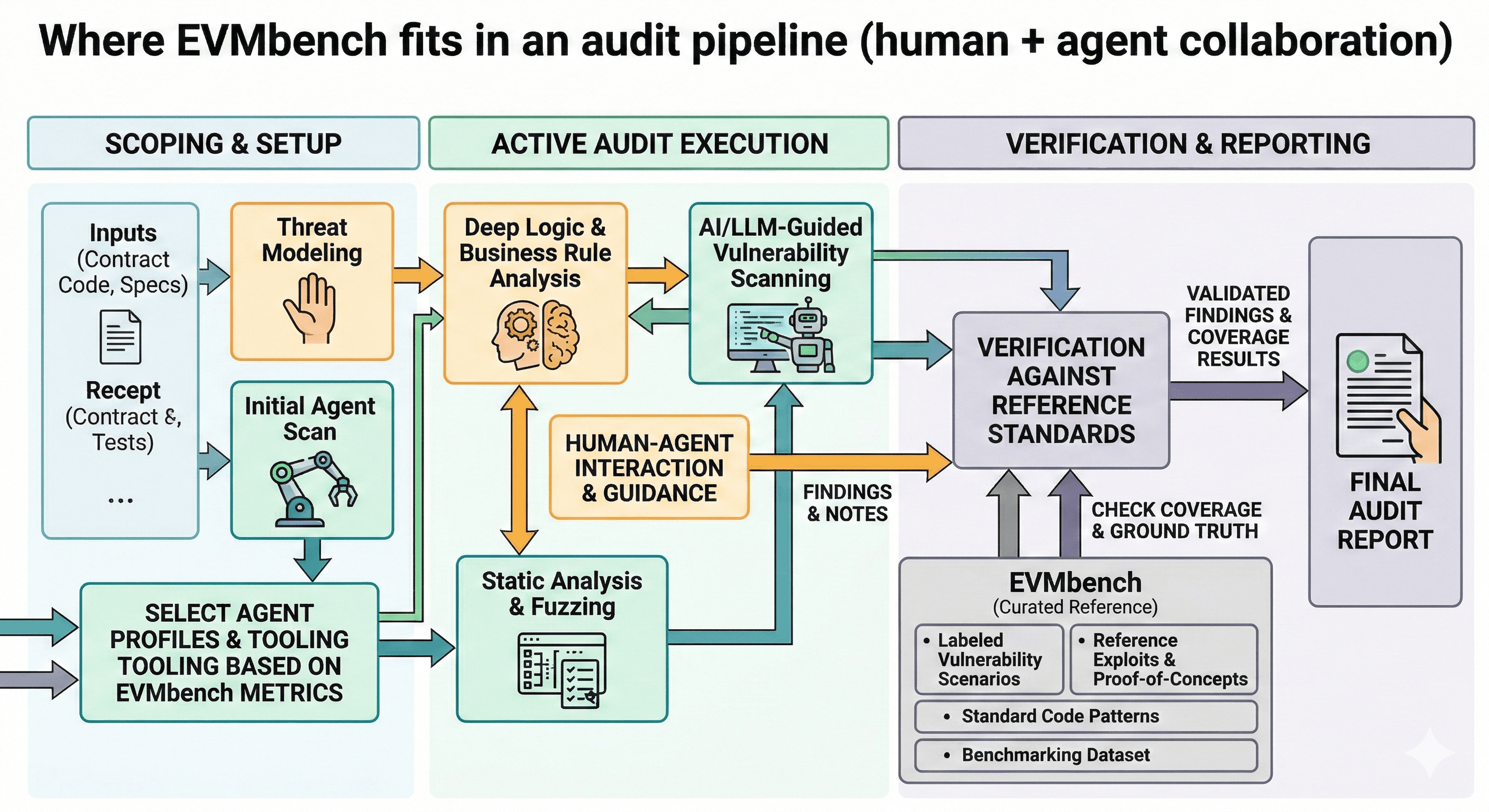
EVMbench is an open evaluation framework and task suite for measuring smart contract security capabilities. It focuses on fund-draining, high-severity vulnerabilities and tests agents in three distinct modes:
1) Detect: Can an agent find the issues?
In Detect mode, an agent audits a contract repository and produces a vulnerability report.
The goal isn’t to “spot something suspicious”. It’s comprehensive coverage: finding the relevant vulnerabilities that are known to exist for that task.
2) Patch: Can an agent fix the vulnerabilities without breaking the contract?
Patch mode evaluates whether an agent can modify a vulnerable codebase so that:
the contract still functions as intended (tests pass), and
the exploit no longer works
This matters because in real engineering teams, the hard part is rarely “a fix exists”; it’s delivering a safe fix that doesn’t introduce a new failure.
3) Exploit: Can an agent execute a real exploit in a controlled environment?
Exploit mode evaluates an agent’s ability to carry out an end-to-end exploit against a local chain instance.
Importantly, this is not about encouraging offensive use. It’s about measuring capability in an economically meaningful domain so that security teams and policymakers can understand what’s possible—and build the right guardrails.
What makes EVMbench different from other security benchmarks?
Most benchmarks focus on narrow subtasks or simplified environments. EVMbench aims to be closer to reality:
it draws on curated real-world vulnerabilities (including many sourced from audit competitions)
it uses an Ethereum-like execution environment so behaviour can be graded programmatically
it separates “agent capability” from “scaffolding” by evaluating different modes and constraints
A particularly useful feature is that the benchmark design emphasises repeatable measurement—so teams can track improvement over time, compare approaches, and see where tooling or workflow decisions change outcomes.
Why smart contract security is a special case for evaluating AI agents
Smart contract security is unusually measurable compared to many other cyber domains:
execution is deterministic
tests can validate behaviour
local chains can simulate realistic state changes
That makes it possible to score agent performance programmatically, which is essential if we want credible, comparable evaluations.
What EVMbench means for security and engineering teams
EVMbench is most useful when you treat it as a capability yardstick, not a product feature.
For security leaders
It provides a clearer way to answer:
How capable are the agents we’re considering?
Where do they fail (coverage, patch safety, end-to-end exploitation)?
What guardrails do we need before using agentic systems in sensitive environments?
For smart contract developers and auditors
It helps teams measure whether a tool:
surfaces real issues reliably (and not just “noise”)
proposes patches that keep functionality intact
can be integrated into CI-style workflows for regression testing
Practical steps: using EVMbench responsibly
If you’re evaluating AI-assisted security tooling, EVMbench can be part of a safe, defensible process.
Step 1: Define your evaluation goal
Be explicit about what you’re measuring:
detection coverage (how many real issues are surfaced)
patch quality (tests pass, exploit fails)
consistency (does performance hold across contract styles and repos)
Step 2: Put governance in place first
Because offensive capability is part of the measurement, governance matters.
Establish:
access controls for any agentic tooling
audit logging and retention
rules for handling exploit-related artefacts
a clear policy for responsible disclosure and escalation
Step 3: Treat the output as decision support, not an autopilot
EVMbench is valuable for benchmarking. In production workflows:
keep human review for critical fixes
require regression tests before merging
track false positives and missed issues as first-class metrics
Step 4: Use results to improve your workflow
The biggest wins often come from process improvements:
better test coverage
clearer threat modelling
structured code review checklists
consistent “definition of done” for patches
How Generation Digital can help
If your team is exploring AI-assisted security—whether in Web3 or broader software assurance—Generation Digital can help you make it practical and safe.
We can support you to:
set up evaluation criteria and governance for agentic tools
design workflows that combine AI support with human review
improve documentation and handoffs so issues are fixed faster
operationalise security work with tools like Asana (tracking and incident workflows) and Notion (policies and playbooks)
Summary
EVMbench is an open benchmark from OpenAI and Paradigm that measures whether AI agents can detect, patch, and exploit high-severity smart contract vulnerabilities in realistic environments. Used responsibly, it gives security teams a way to track capability, understand failure modes, and build safer, more reliable defensive workflows.
Next steps: If you’re assessing AI-assisted security or want help building governance around agentic tooling, speak to Generation Digital.
FAQs
What is EVMbench?
EVMbench is an open benchmark created by OpenAI and Paradigm to evaluate AI agents on smart contract security tasks—detecting vulnerabilities, patching them safely, and exploiting them in controlled environments.
How does EVMbench benefit developers?
It helps developers and auditors measure tooling performance, identify gaps (coverage, patch safety, consistency), and improve security workflows using repeatable, programmatic evaluation.
Why focus on smart contracts?
Smart contracts manage high-value assets and are difficult to remediate after deployment. Measuring detection and patch quality—and understanding exploitability—helps reduce risk and improve reliability.
Does EVMbench encourage offensive hacking?
EVMbench includes exploit evaluation to measure real capability and risk in a controlled setting. Security teams can use those insights to build guardrails, improve monitoring, and prioritise defensive practices.
How should organisations use results in practice?
Use EVMbench scores to compare approaches, track improvements over time, and inform governance. In production, keep human review, regression testing, and clear disclosure processes for any discovered issues.
Recibe noticias y consejos sobre IA cada semana en tu bandeja de entrada
Al suscribirte, das tu consentimiento para que Generation Digital almacene y procese tus datos de acuerdo con nuestra política de privacidad. Puedes leer la política completa en gend.co/privacy.



Generación
Digital

Oficina en Reino Unido
Generation Digital Ltd
33 Queen St,
Londres
EC4R 1AP
Reino Unido
Oficina en Canadá
Generation Digital Americas Inc
181 Bay St., Suite 1800
Toronto, ON, M5J 2T9
Canadá
Oficina en EE. UU.
Generation Digital Américas Inc
77 Sands St,
Brooklyn, NY 11201,
Estados Unidos
Oficina de la UE
Software Generación Digital
Edificio Elgee
Dundalk
A91 X2R3
Irlanda
Oficina en Medio Oriente
6994 Alsharq 3890,
An Narjis,
Riad 13343,
Arabia Saudita







Número de la empresa: 256 9431 77 | Derechos de autor 2026 | Términos y Condiciones | Política de Privacidad