Experience Real-Time Coding with GPT-5.3-Codex-Spark
ChatGPT

Pas sûr de quoi faire ensuite avec l'IA?Évaluez la préparation, les risques et les priorités en moins d'une heure.
➔ Téléchargez notre kit de préparation à l'IA gratuit
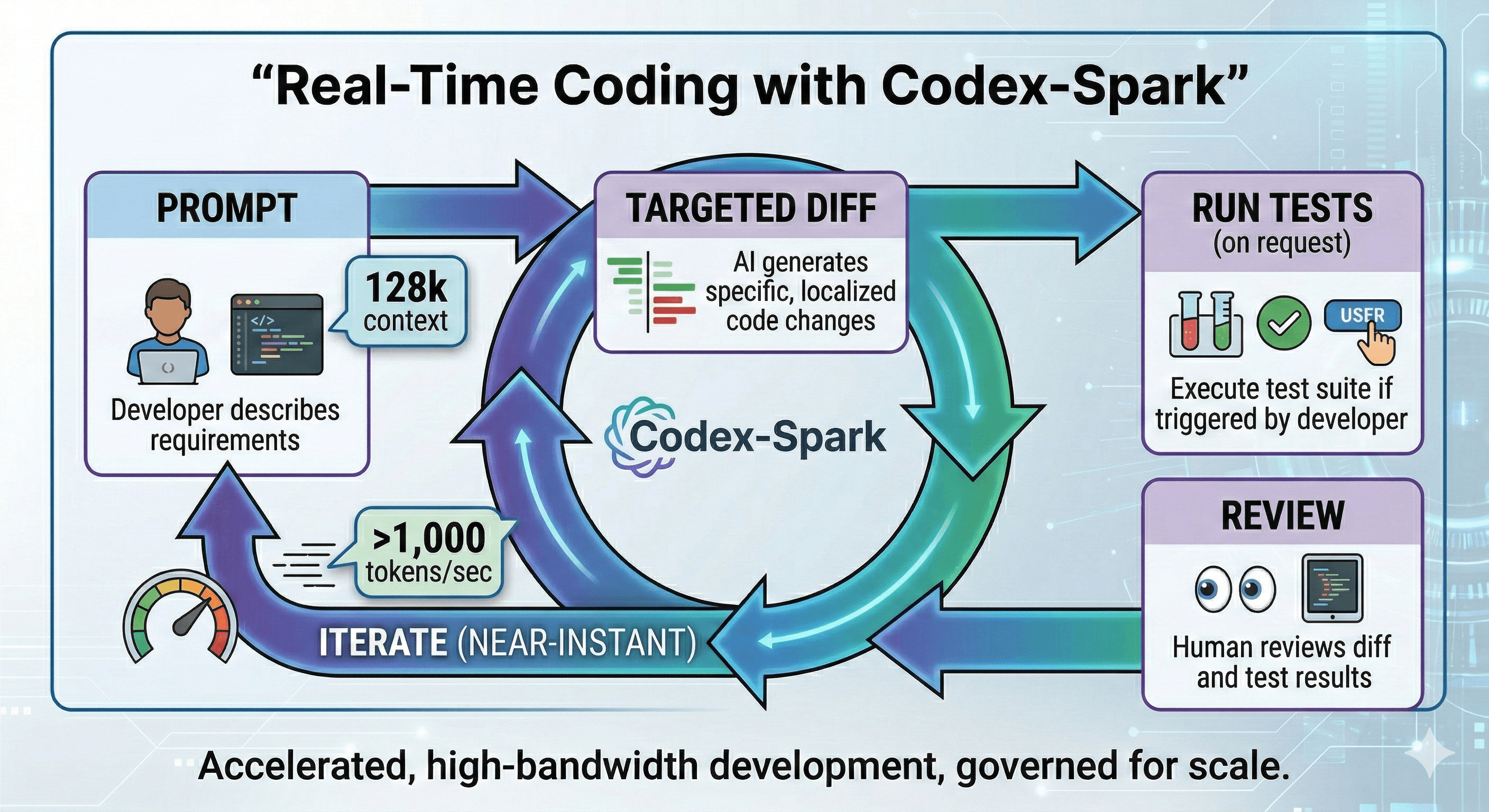
GPT‑5.3‑Codex‑Spark is OpenAI’s first real-time coding model for Codex, built for near-instant iteration. It delivers over 1,000 tokens per second, supports a 128k context window, and is available as a research preview for ChatGPT Pro users in the Codex app, CLI and VS Code extension. It’s tuned for fast, targeted edits rather than long, autonomous runs.
“Faster AI” only matters if it changes how you build.
OpenAI’s GPT‑5.3‑Codex‑Spark is designed to do exactly that: it’s the first Codex model built for real-time coding, where latency is low enough that you can iterate like you’re pairing with someone sitting next to you.
Released as a research preview on 12 February 2026, Codex‑Spark is a smaller version of GPT‑5.3‑Codex, optimised for ultra‑low latency inference—reportedly delivering more than 1,000 tokens per second, with a 128k context window at launch. It’s currently text-only.
What’s new: real-time coding inside Codex
Codex‑Spark is built for the moments where speed matters as much as intelligence:
targeted edits,
rapid refactors,
quick interface iterations,
and tight feedback loops where you want to steer mid-stream.
OpenAI notes that Codex‑Spark keeps its default working style lightweight: it prefers minimal, targeted changes and doesn’t run tests automatically unless you ask. That’s exactly what you want for fast iteration: fewer “big rewrites”, more precise loops.
Who can access GPT‑5.3‑Codex‑Spark?
At launch, Codex‑Spark is rolling out as a research preview for ChatGPT Pro users in the latest versions of:
the Codex app,
the Codex CLI,
and the VS Code extension.
During the preview it uses separate rate limits, and OpenAI notes you may see limited access or queuing when demand is high.
Where Codex‑Spark fits in a modern dev workflow
Think of Codex‑Spark as the “fast lane” for coding:
Best for
tight edit → run → refine loops
small, safe refactors
targeted bug fixes
quick code generation and scaffolding
interface tweaks and incremental improvements
Less ideal for
long-running, multi-hour autonomous work
complex architecture redesigns that need deeper reasoning
high-risk changes without strong test coverage
In other words: use Spark to stay in flow, and switch to deeper models when the problem demands it.
How to prompt Codex‑Spark for better results
Speed doesn’t replace clarity. Strong prompts make the model faster and more accurate.
Use this simple structure:
Goal (what you want done)
Constraints (what must not change)
Context (file/module purpose, relevant APIs, expected behaviour)
Acceptance criteria (how you’ll verify it worked)
Output format (diff-style edits, list of changes, tests to run)
Prompt template (copy/paste)
“Make a targeted change to achieve [goal]. Do not change [constraints]. Context: [brief]. Acceptance criteria: [bullets]. Output: propose the smallest diff, then list tests I should run.”
Example prompts
“Refactor this function to remove duplication without changing behaviour. Keep the public API identical. Output the smallest diff and add unit tests for the edge cases.”
“Fix the bug where null values crash the parser. Don’t change the parsing rules. Provide a minimal patch and a regression test.”
“Improve performance for this loop. Keep output identical. Suggest micro-optimisations first; only restructure if needed.”
Practical steps: getting value in week one
If you want early wins, focus on measurable “developer minutes saved” rather than chasing perfect end-to-end automation.
Step 1: Choose one workflow to accelerate
Pick something frequent:
code review fixes,
small refactors,
test generation for a module,
documentation updates,
repetitive UI changes.
Step 2: Standardise your prompting patterns
Create a shared set of “known-good” prompts (bugfix, refactor, tests, docs) and publish them.
Step 3: Add lightweight guardrails
Require:
diffs rather than full rewrites,
explicit acceptance criteria,
and a test plan for any functional change.
Step 4: Track outcomes
Measure:
cycle time for small tasks,
PR turnaround time,
fewer review iterations,
and reduction in repetitive work.
How teams can operationalise adoption
Codex‑Spark becomes more valuable when teams use it consistently and safely.
Use Asana to run an adoption plan (owners, rollout waves, metrics).
Use Miro to map your “AI-assisted dev workflow” and agree review gates.
Use Notion to host prompt libraries, coding standards, and examples.
Use Glean to make those standards searchable so people (and AI) can find the right patterns fast.
Summary
GPT‑5.3‑Codex‑Spark is a meaningful shift: real-time coding assistance with near-instant generation speed and long context, designed for interactive iteration rather than long autonomous runs.
If your teams want to move from occasional AI usage to consistent productivity gains, the biggest lever is operational: standard prompts, small safe workflows, and measurable outcomes.
Next steps
Try Codex‑Spark on one repeatable task category.
Save the best prompt as a team template.
Require acceptance criteria and a test plan.
Measure time saved, then scale.
FAQ
Q1: What is GPT‑5.3‑Codex‑Spark?
GPT‑5.3‑Codex‑Spark is OpenAI’s real-time coding model for Codex, optimised for ultra-low latency and rapid iteration. It’s a smaller version of GPT‑5.3‑Codex.
Q2: Who can access GPT‑5.3‑Codex‑Spark?
It’s currently available as a research preview for ChatGPT Pro users in the Codex app, Codex CLI and VS Code extension.
Q3: What are the headline improvements?
OpenAI positions Codex‑Spark as 15× faster than GPT‑5.3‑Codex for generation speed, with a 128k context window and near-instant responses.
Q4: Is Codex‑Spark available via the API?
OpenAI has stated it’s available in the API for a small set of design partners during the research preview.
Q5: What’s the best way to use Codex‑Spark?
Use it for fast, targeted edits and quick iteration loops. Ask explicitly for tests to be run or for a test plan, since the model defaults to lightweight edits.
Recevez chaque semaine des nouvelles et des conseils sur l'IA directement dans votre boîte de réception
En vous abonnant, vous consentez à ce que Génération Numérique stocke et traite vos informations conformément à notre politique de confidentialité. Vous pouvez lire la politique complète sur gend.co/privacy.



Génération
Numérique

Bureau du Royaume-Uni
Génération Numérique Ltée
33 rue Queen,
Londres
EC4R 1AP
Royaume-Uni
Bureau au Canada
Génération Numérique Amériques Inc
181 rue Bay, Suite 1800
Toronto, ON, M5J 2T9
Canada
Bureau aux États-Unis
Generation Digital Americas Inc
77 Sands St,
Brooklyn, NY 11201,
États-Unis
Bureau de l'UE
Génération de logiciels numériques
Bâtiment Elgee
Dundalk
A91 X2R3
Irlande
Bureau du Moyen-Orient
6994 Alsharq 3890,
An Narjis,
Riyad 13343,
Arabie Saoudite







Numéro d'entreprise : 256 9431 77 | Droits d'auteur 2026 | Conditions générales | Politique de confidentialité