Les Modèles RAG : Accroître la Précision de l'IA en Entreprise en 2026
Gémeaux
Pérplexité
OpenAI
Claude
ChatGPT
Pas sûr de quoi faire ensuite avec l'IA?Évaluez la préparation, les risques et les priorités en moins d'une heure.
➔ Téléchargez notre kit de préparation à l'IA gratuit
Pourquoi RAG est important en 2026
RAG est passé d'un prototype prometteur à un modèle d'entreprise fiable. En 2026, la précision n'est plus seulement un objectif de qualité, c'est une exigence de conformité. En basant chaque réponse sur des documents cités, RAG rend les sorties vérifiables pour les examens internes et les régulateurs externes. Il raccourcit également le cycle de mise à jour : lorsque les politiques, les spécifications de produits ou les prix changent, vous mettez à jour l'index au lieu de réentraîner un modèle, permettant ainsi aux équipes de répondre aux changements en quelques heures plutôt qu'en plusieurs mois. Tout aussi important, RAG peut être rentable. Des modèles plus petits et bien régulés associés à une récupération solide surpassent régulièrement les modèles lourds travaillant à partir de la mémoire seule pour les questions-réponses d'entreprise. Et comme le contenu vit à l'intérieur d'indices contrôlés, vous pouvez appliquer des règles d'accès, modifier des champs sensibles et conserver les données dans votre région choisie, intégrant la confidentialité par conception dans vos opérations quotidiennes.
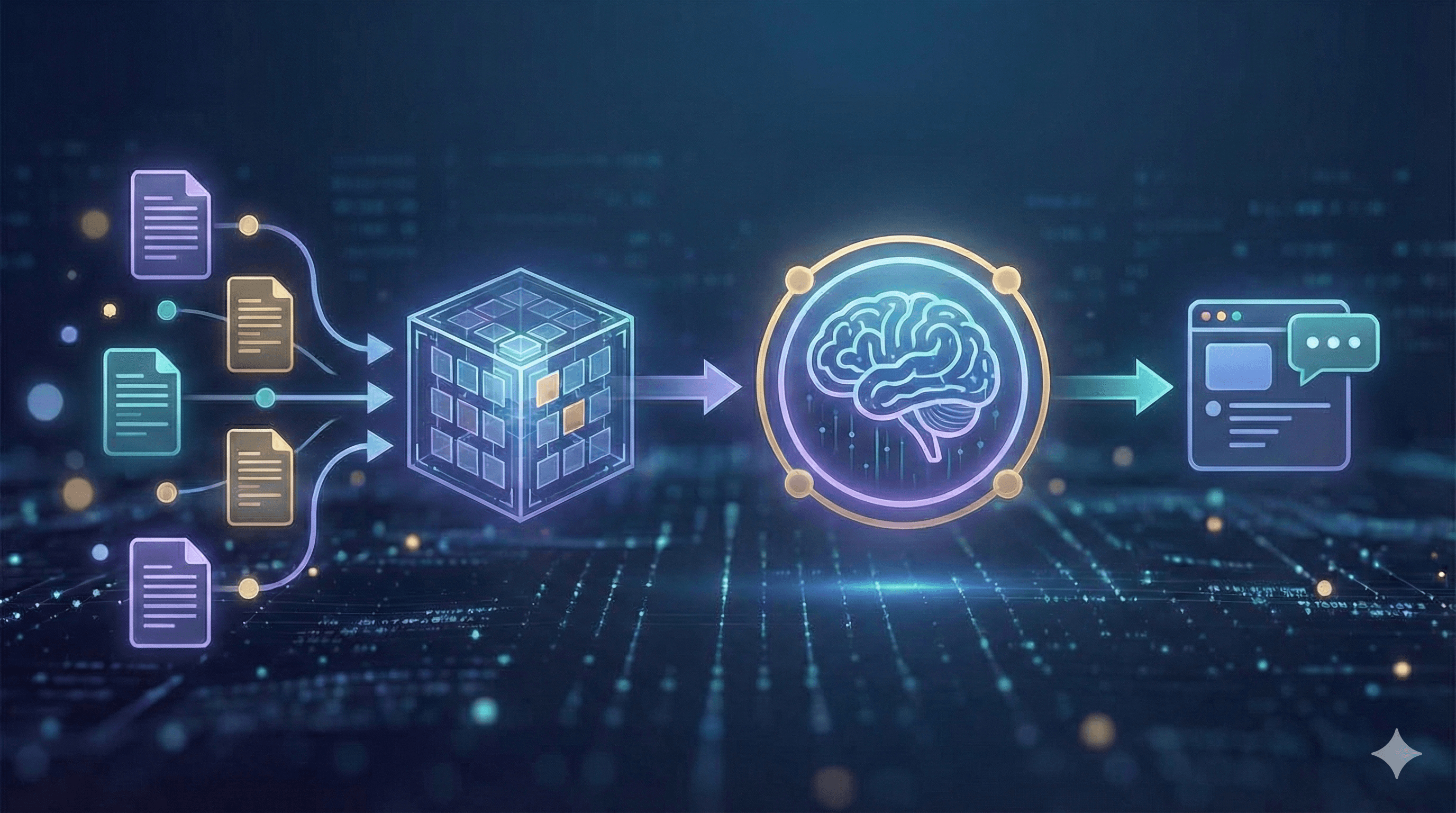
Comment fonctionne RAG (vue moderne)
Un système RAG moderne commence par l'ingestion : vous enregistrez les sources importantes — politiques, wikis, tickets, PDF et données structurées — puis les nettoyez, dédupliquez et étiquetez avec des métadonnées utiles telles que le propriétaire, la date et la région. Vient ensuite le fragmentation et l'intégration. Plutôt que de découper le texte de manière arbitraire, vous conservez les titres et sections pour que chaque fragment soit suffisamment contextuel pour avoir du sens, puis stockez les intégrations dans un index vectoriel sécurisé, accompagnés de champs de mots-clés pour des correspondances exactes.
Au moment de la requête, l'assistant récupère un ensemble réduit de passages prometteurs utilisant une recherche hybride qui combine des vecteurs sémantiques avec des filtres de mots-clés classiques (pour les références SKU, les acronymes et les dates). Un re-réseau léger peut réorganiser ces candidats pour que seuls les cinq ou six plus pertinents passent. Le système augmente alors le prompt avec ces passages, des instructions et des garde-fous (par exemple : répondre de manière concise, citer des sources, et refuser si les preuves manquent). Un LLM réglementé génère la réponse et retourne les citations et liens profonds afin que les utilisateurs puissent inspecter les originaux. Enfin, vous évaluez et surveillez en continu — en suivant la fidélité, la latence et le coût avec des tests automatisés, et en révisant manuellement des échantillons pour maintenir une haute qualité.
Principaux avantages
Les entreprises adoptent RAG pour quatre raisons. Premièrement, les réponses sont précises et à jour parce qu'elles se basent sur les documents les plus récents plutôt que sur la mémoire obsolète d'un modèle. Deuxièmement, la maintenance baisse : vous mettez à jour un index, pas un modèle, ce qui est idéal pour les politiques et données de produits en constante évolution. Troisièmement, RAG offre une origine prouvée — les citations permettent aux employés et clients de vérifier les affirmations en un clic. Et quatrièmement, vous obtenez une confidentialité configurable via un accès basé sur les rôles, la modification et les journaux d'audit, gardant les connaissances sensibles à l'intérieur de votre environnement.
Modèles d'architecture
Commencez avec le RAG classique — la recherche vectorielle renvoie les passages top-k que vous passez au modèle. C'est rapide et établit un point de référence mesurable. La plupart des entreprises passent rapidement au RAG hybride, combinant des vecteurs avec des filtres de mots-clés et des facettes de métadonnées pour gérer des éléments comme les numéros de pièce et les dates d'application. Lorsque la qualité doit être maximisée, introduisez un pipeline reclassé : récupérez largement (par exemple, k≈50) et laissez un cross-encodeur promouvoir les cinq meilleurs pour le prompt.
Pour les questions complexes, la récupération multi-sauts ou agentique planifie un court parcours de recherche — en lisant une politique, en suivant une exception, puis en ouvrant le formulaire pertinent. Enfin, RAG structuré mélange texte non structuré avec tableaux et JSON, permettant à l'assistant d'appeler des outils ou SQL pour les faits au lieu de paraphraser les chiffres à partir du texte.
Étapes pratiques
1) Préparation des données
Commencez par un registre des sources pour savoir quels sites SharePoint, Drives, espaces Confluence, files d'attente de tickets et bases de données de produits alimenteront l'assistant. Conservez les titres, les listes et les tableaux lors de la conversion, éliminez le remplissage et les signatures, et divisez le contenu en sections de 200 à 600 tokens qui héritent de leurs titres parents. Attachez des métadonnées telles que le propriétaire, le produit, la région (UK/EU), la date d'application et l'étiquette de sécurité. Pour les données personnelles, réduisez au minimum ou modifiez avant l'indexation et enregistrez la base légale pour le traitement.
2) Récupération & invitation
Utilisez la recherche hybride (BM25 plus vecteurs) et appliquez des filtres comme région:UK ou statut:actuel. Gardez le prompt du système explicite : “Répondez uniquement en utilisant le contexte fourni ; incluez des citations ; si les preuves manquent, dites ‘Non trouvé’.” Limitez le contexte à quelques passages de haute qualité plutôt que des douzaines de passages bruyants et vous verrez à la fois la latence et les hallucinations diminuer.
3) Évaluation & surveillance
Assemblez un ensemble doré de questions représentatives avec des réponses et des références véridiques, puis suivez la fidélité, la précision/rappel du contexte, la pertinence de la réponse, la latence et le coût. En production, recueillez les pouces vers le haut/bas avec des raisons et analysez les événements
Recevez chaque semaine des nouvelles et des conseils sur l'IA directement dans votre boîte de réception
En vous abonnant, vous consentez à ce que Génération Numérique stocke et traite vos informations conformément à notre politique de confidentialité. Vous pouvez lire la politique complète sur gend.co/privacy.



Génération
Numérique

Bureau du Royaume-Uni
Génération Numérique Ltée
33 rue Queen,
Londres
EC4R 1AP
Royaume-Uni
Bureau au Canada
Génération Numérique Amériques Inc
181 rue Bay, Suite 1800
Toronto, ON, M5J 2T9
Canada
Bureau aux États-Unis
Generation Digital Americas Inc
77 Sands St,
Brooklyn, NY 11201,
États-Unis
Bureau de l'UE
Génération de logiciels numériques
Bâtiment Elgee
Dundalk
A91 X2R3
Irlande
Bureau du Moyen-Orient
6994 Alsharq 3890,
An Narjis,
Riyad 13343,
Arabie Saoudite







Numéro d'entreprise : 256 9431 77 | Droits d'auteur 2026 | Conditions générales | Politique de confidentialité