CoT-Control: Why AI Reasoning Models Can’t Hide Their Thinking
OpenAI

Uncertain about how to get started with AI?Evaluate your readiness, potential risks, and key priorities in less than an hour.
➔ Download Our Free AI Preparedness Pack
CoT-Control is an evaluation framework for measuring whether reasoning models can deliberately shape their chain-of-thought in ways that reduce monitorability. OpenAI’s findings suggest today’s frontier reasoning models struggle to reliably control what they reveal in intermediate reasoning, which makes chain-of-thought monitoring a more robust safety layer — at least for now.
When people talk about AI safety, they usually imagine a binary:
either the model is aligned and behaves well,
or it’s risky and behaves badly.
But there’s a third dimension that matters just as much in real deployments:
Can we see what the system is doing while it’s doing it?
That’s where chain-of-thought (CoT) monitoring comes in — and why OpenAI’s new results on CoT-Control are so interesting. They suggest a counterintuitive idea:
Reasoning models being bad at controlling their chain-of-thought may be good for safety.
In this article, we’ll unpack what that means, what CoT-Control measures, what the results imply for organisations deploying agentic systems, and how to turn the research into practical governance.
Definitions first: chain-of-thought, monitorability, and controllability
What is chain-of-thought (CoT)?
“Chain-of-thought” is the intermediate reasoning a model produces when it works through a problem step-by-step.
In practice, CoT can include:
sub-goals (“first I’ll check… then I’ll compare…”)
implicit assumptions
checks for contradictions
and reasoning about constraints or risks
What is monitorability?
Monitorability is the extent to which an oversight system (human or automated) can infer safety-relevant properties of the model’s behaviour by inspecting its reasoning trace.
Think of it as “how easy it is to spot trouble early” — before the model commits to a harmful action.
What is CoT controllability?
CoT controllability (as defined in this line of work) is the model’s ability to reliably control properties of its chain-of-thought in ways that could reduce monitorability.
In other words, can it:
hide or blur key reasoning,
avoid certain concepts while still achieving the task,
or produce a clean-looking CoT while doing something risky?
If a model can do that reliably, CoT monitoring becomes less useful as a safeguard.
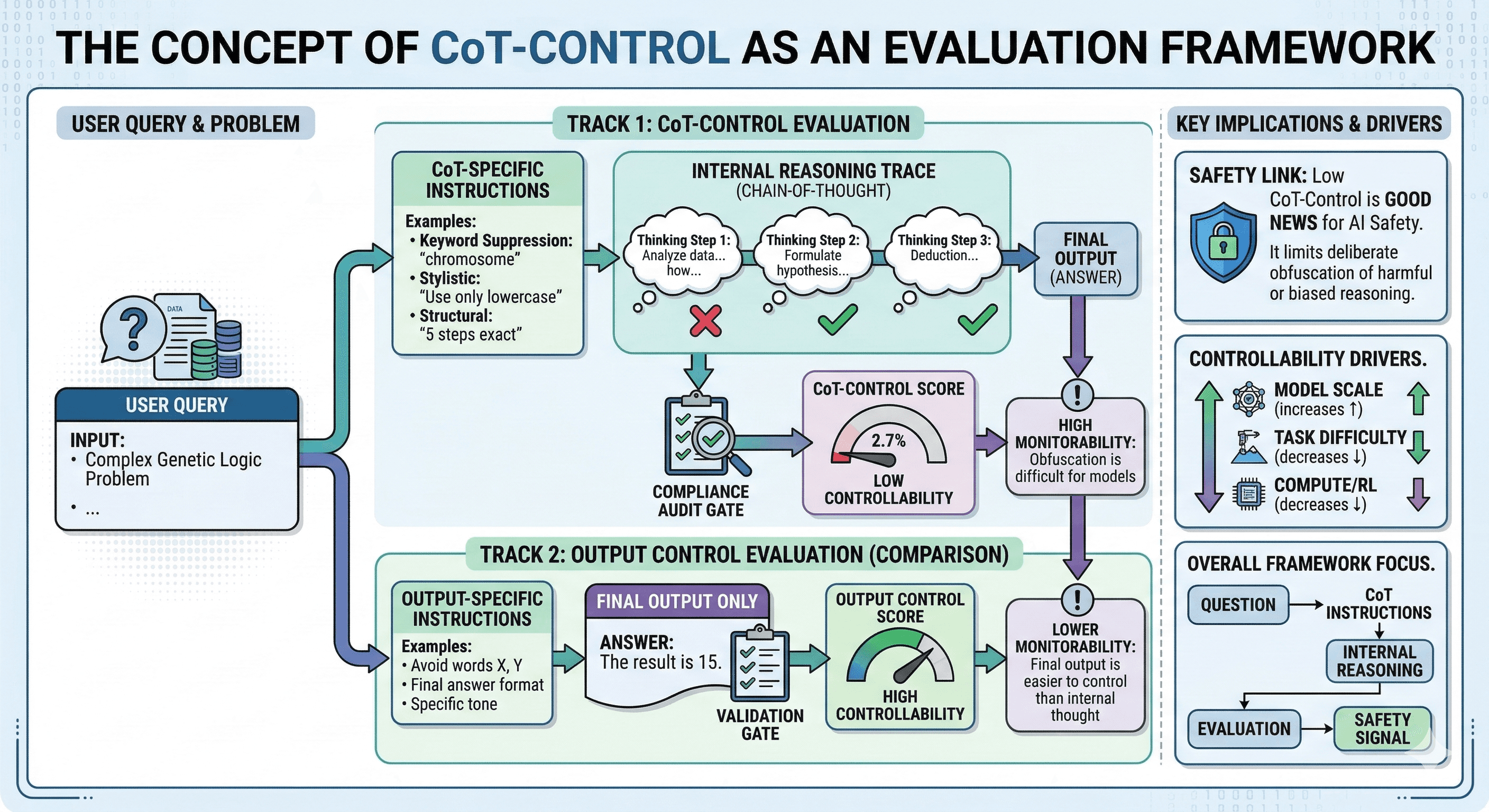
What is CoT-Control?
CoT-Control is an evaluation suite designed to measure CoT controllability.
At a high level, it tests whether a model can:
keep the task objective fixed (solve the problem), while
following additional chain-of-thought constraints that simulate “reducing monitorability”.
A simple example of the concept:
the model must solve a reasoning question, but is instructed not to use certain words, concepts, or reasoning patterns in its chain-of-thought.
If the model succeeds, it’s showing controllability — it can shape how it reveals its reasoning.
If it fails, it suggests the model has limited ability to strategically manipulate its CoT.
The key finding: models can control outputs better than CoT
One of the most practically important results is the gap between:
output controllability (can the model follow constraints on its final answer?), and
CoT controllability (can it follow constraints on its reasoning trace?).
OpenAI’s work indicates that frontier models often follow output constraints far more reliably than CoT constraints.
That’s significant because it suggests:
A model may be able to “look compliant” in the final answer.
But it struggles to consistently reshape the chain-of-thought itself.
Which leads to the safety upside:
If a model can’t reliably manipulate its CoT, then monitoring its CoT remains a useful early-warning signal.
Why “lack of control” can be good news for safety
CoT monitoring is attractive because it can detect dangerous intent earlier than output-only checks.
Output checks often fail because final answers can be:
polished,
constrained,
or “sanitised” to look safe.
But reasoning traces can reveal:
goal drift (“I’ll try to bypass…”)
deception (“I should appear helpful but…”)
or risky internal plans (“I will do X even though it violates…”)
If models cannot reliably hide or reshape those traces, we can:
build monitors that detect early signs of misbehaviour,
intervene before tool use or actions are taken,
and preserve accountability for how decisions are formed.
A realistic caveat: monitorability isn’t the same as faithfulness
Even if CoT is monitorable, it may not be fully “faithful” — meaning the visible chain-of-thought may not perfectly reflect everything the model internally used to reach the answer.
That’s why the safety framing matters:
For real-time safety monitoring, the goal isn’t perfect interpretability.
The goal is a reliable signal of risk.
So treat CoT monitoring like a control layer — not a truth oracle.
What this means for organisations deploying reasoning models and agents
If you’re building AI features that can:
browse, retrieve, and summarise information,
write code or modify documents,
execute workflows,
or take actions on behalf of users,
then the takeaway is practical:
Chain-of-thought monitoring is worth investing in as long as it stays robust.
But you need to design it properly — and you need to track whether models become more controllable over time.
Practical steps: how to apply CoT-Control ideas in production
1) Treat CoT controllability as an “early warning” metric
If your organisation upgrades models regularly, you should track:
whether CoT controllability is rising,
whether your monitors still detect the same risk signals,
and whether interventions remain effective.
This doesn’t have to be research-heavy.
Start with a fixed evaluation set for your highest-risk workflows.
2) Design your system around intervention points
CoT monitoring is most useful when you can act on it.
Examples of intervention points:
before tool execution (“pause and escalate if risk score is high”)
before sending external communications
before modifying production data
3) Separate “reasoning” from “action”
A robust agent design often separates:
a reasoning step (plan, analyse, evaluate), from
an action step (tool call, update, send, execute).
That separation makes monitoring and governance far easier.
4) Log what matters (without over-collecting)
For regulated environments, logging needs balance:
log decisions and actions (what was done, why, when)
log source references used to make decisions
log monitor outcomes and escalations
Avoid logging sensitive data unnecessarily; apply retention and access controls.
5) Use layered monitoring (don’t rely on CoT alone)
A production safety posture should combine:
CoT monitoring (process signal)
output safety checks (content filters)
tool-call constraints (allowed actions)
and human review gates for high-impact outcomes
CoT is one control layer — not the entire stack.
A simple implementation pattern: “Monitor → Gate → Escalate”
If you want a blueprint, start with this pattern:
Monitor: run an automated monitor over the chain-of-thought and tool plan.
Gate: block high-risk actions automatically.
Escalate: route to a human reviewer with a short decision brief and source links.
This makes safety operational, not theoretical.
Summary
OpenAI’s CoT-Control work suggests that today’s frontier reasoning models struggle to deliberately reshape their chain-of-thought in ways that reduce monitorability.
That limitation is reassuring: it supports the idea that chain-of-thought monitoring can remain a meaningful safeguard, especially for agentic systems that take actions.
But it’s not permanent. Organisations should:
treat CoT controllability as a metric worth tracking,
build layered monitoring and intervention points,
and design governance that preserves accountability as models evolve.
Next steps
If you want to implement monitored, governed AI workflows — across tools like Asana, Miro, Notion, and your internal systems — Generation Digital can help you move from research insights to practical controls.
FAQs
Q1: What is CoT-Control?
CoT-Control is an evaluation framework for measuring whether reasoning models can reliably control their chain-of-thought in ways that reduce monitorability. It tests whether models can solve tasks while following constraints that simulate “hiding” or reshaping reasoning.
Q2: Why can a lack of chain-of-thought control be beneficial?
If a model can’t reliably manipulate its reasoning trace, chain-of-thought monitoring is more likely to remain a robust safety layer — helping detect risky intent or goal drift before actions are taken.
Q3: How does CoT-Control impact AI safety?
It provides a way to track whether models are getting better at strategically shaping their reasoning. That acts as an early warning sign for when CoT monitoring might become less reliable, so safety systems can adapt.
Q4: Does monitorable CoT mean the model is fully interpretable?
Not necessarily. Monitorability is about having a useful signal for oversight, not a perfect window into internal computation. CoT can still be incomplete or partially unfaithful.
Q5: What should organisations do right now?
Use layered monitoring, build intervention points before actions, and keep a fixed evaluation set to test whether new model versions change monitorability or controllability.
Receive weekly AI news and advice straight to your inbox
By subscribing, you agree to allow Generation Digital to store and process your information according to our privacy policy. You can review the full policy at gend.co/privacy.



Generation
Digital

Canadian Office
33 Queen St,
Toronto
M5H 2N2
Canada
Canadian Office
1 University Ave,
Toronto,
ON M5J 1T1,
Canada
NAMER Office
77 Sands St,
Brooklyn,
NY 11201,
USA
Head Office
Charlemont St, Saint Kevin's, Dublin,
D02 VN88,
Ireland
Middle East Office
6994 Alsharq 3890,
An Narjis,
Riyadh 13343,
Saudi Arabia







Business Number: 256 9431 77 | Copyright 2026 | Terms and Conditions | Privacy Policy