Glean Enterprise Search: Preferred 1.9× vs ChatGPT
Exploiter
Pas sûr de quoi faire ensuite avec l'IA?Évaluez la préparation, les risques et les priorités en moins d'une heure.
➔ Téléchargez notre kit de préparation à l'IA gratuit
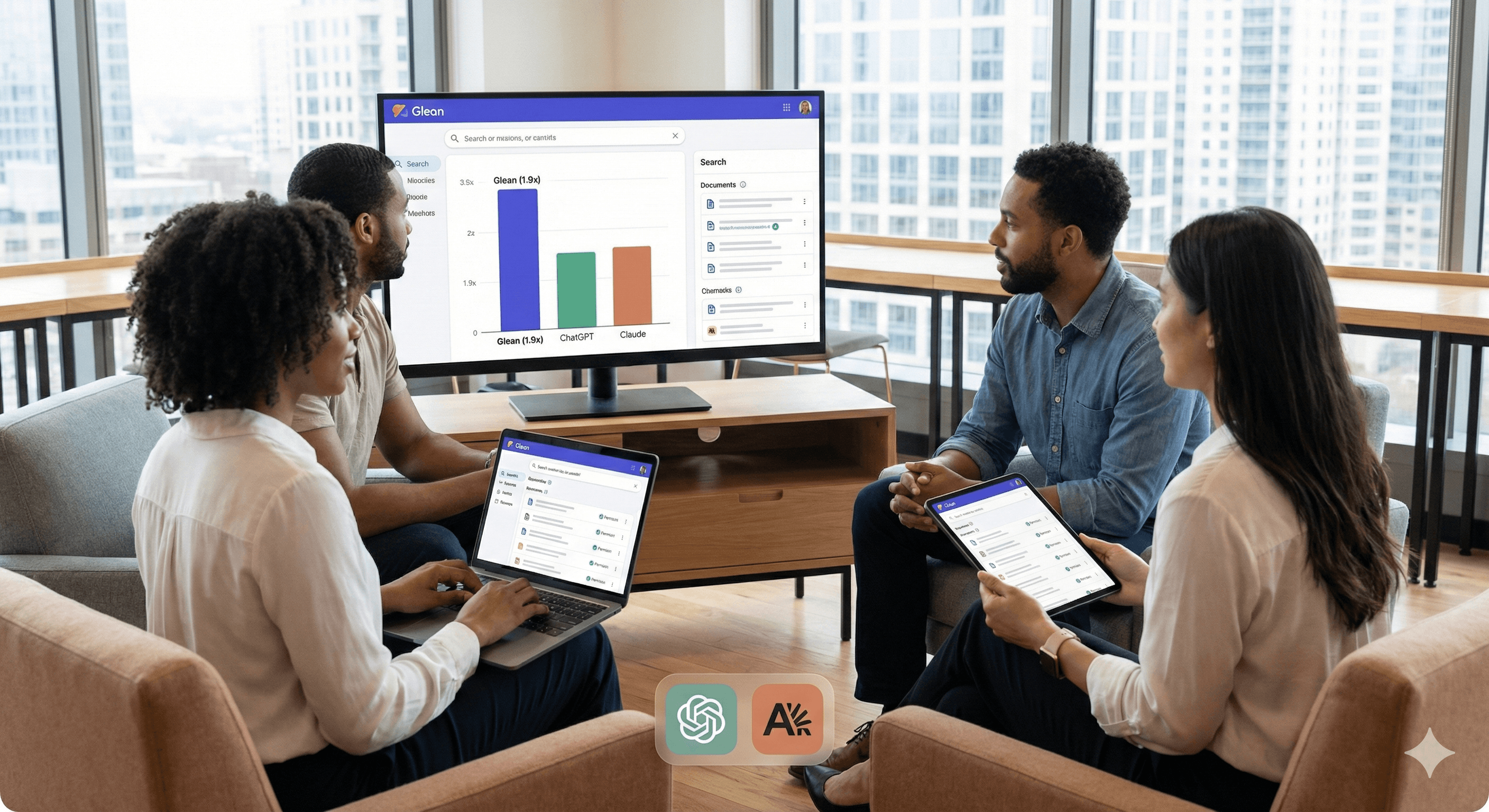
Glean reports that in a recent enterprise search evaluation, human graders chose Glean’s answers as correct 1.9× more often than ChatGPT and 1.6× more often than Claude—when graders had a preference. The results highlight how permission-aware indexing and stronger enterprise context can improve answer accuracy in workplace environments.
Enterprise search is only useful if it’s right, permission-aware, and grounded in the context of how your organisation actually works. Glean has published new evaluation results suggesting its enterprise answers are preferred significantly more often than comparable outputs from ChatGPT company knowledge and Claude enterprise search.
In Glean’s evaluation, when human graders expressed a preference, they selected Glean’s response as correct 1.9× more often than ChatGPT and 1.6× more often than Claude (based on Glean’s win–loss ratio approach for correctness).
What the evaluation actually says (and what it doesn’t)
Glean’s headline numbers are compelling, but it’s important to read them precisely:
The ratios apply only in cases where graders had a preference (not every query necessarily produced a strong winner).
The evaluation is published by Glean, so it’s best treated as strong directional evidence—not the final word. You should still validate against your own data, access controls and use cases.
That said, the results align with what many organisations experience in practice: the hardest part of “AI search” isn’t the model—it’s the enterprise context layer.
Why enterprise context often decides the winner
Glean attributes its performance to how it builds and uses context, including:
indexed enterprise data for fast retrieval
an “Enterprise Graph” approach to relationships and signals
“enterprise memory” (via trace learning) to optimise tool use over time
Whether you agree with Glean’s framing or not, the underlying point is useful: good retrieval + permissions + relevance signals usually beats a generic assistant that’s missing your organisation’s structure.
Practical steps: how to validate “2× better” claims in your own organisation
If you’re considering Glean (or comparing it to ChatGPT/Claude enterprise offerings), here’s a simple way to sanity-check results quickly:
Pick 25–50 real internal questions people ask weekly (policies, project context, customer FAQs, onboarding, technical docs).
Run a blinded test: remove vendor names and ask evaluators to score correctness, citations/links, and whether the answer respects permissions.
Segment by use case: decision-making queries tend to behave differently from “find the doc” queries.
Track failure modes: hallucinations, stale docs, missing permissions, or overly generic responses.
This approach will tell you whether the “preference ratio” holds for your own knowledge base—where it matters.
Summary
Glean reports that human graders selected its answers as correct 1.9× more often than ChatGPT and 1.6× more often than Claude in a recent enterprise context evaluation—when graders had a preference. If your organisation is struggling with reliable, permission-aware knowledge discovery, it’s worth testing Glean alongside your existing enterprise AI tools using a controlled, internal benchmark.
Next steps: Explore the Glean page on Generation Digital and speak to us about evaluation frameworks, governance, and rollout planning.
FAQ
Q1: Why is Glean preferred over ChatGPT in this evaluation?
Glean reports that when graders had a preference, they chose Glean over ChatGPT 1.9× more often for correctness, which the paper links to stronger enterprise context construction.
Q2: How does Glean compare to Claude?
In the same evaluation, Glean reports it was chosen 1.6× more often than Claude when graders had a preference on correctness.
Q3: What makes enterprise search “good” in practice?
The key differentiators are typically permission-aware retrieval, relevance ranking, up-to-date indexing, and the ability to pull the right context fo
Recevez chaque semaine des nouvelles et des conseils sur l'IA directement dans votre boîte de réception
En vous abonnant, vous consentez à ce que Génération Numérique stocke et traite vos informations conformément à notre politique de confidentialité. Vous pouvez lire la politique complète sur gend.co/privacy.



Génération
Numérique

Bureau du Royaume-Uni
Génération Numérique Ltée
33 rue Queen,
Londres
EC4R 1AP
Royaume-Uni
Bureau au Canada
Génération Numérique Amériques Inc
181 rue Bay, Suite 1800
Toronto, ON, M5J 2T9
Canada
Bureau aux États-Unis
Generation Digital Americas Inc
77 Sands St,
Brooklyn, NY 11201,
États-Unis
Bureau de l'UE
Génération de logiciels numériques
Bâtiment Elgee
Dundalk
A91 X2R3
Irlande
Bureau du Moyen-Orient
6994 Alsharq 3890,
An Narjis,
Riyad 13343,
Arabie Saoudite







Numéro d'entreprise : 256 9431 77 | Droits d'auteur 2026 | Conditions générales | Politique de confidentialité