Gemini Model Extraction Attacks: How ‘AI Cloning’ Works
Gemini

Uncertain about how to get started with AI?Evaluate your readiness, potential risks, and key priorities in less than an hour.
➔ Download Our Free AI Preparedness Pack
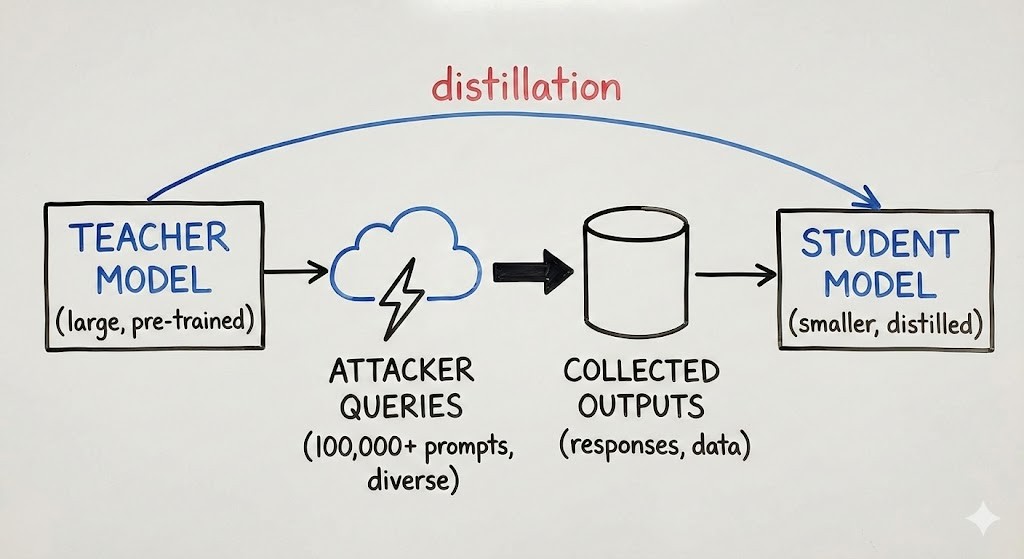
Model extraction (distillation) attacks try to “clone” an AI model by sending large volumes of carefully designed prompts and using the outputs to train a copycat system. Google says Gemini has faced 100,000+ prompt campaigns, including attempts to coerce reasoning traces. The biggest risk is IP theft for AI providers — mitigated through abuse detection and access controls. (eweek.com)
As generative AI becomes more powerful, the threat landscape is changing with it. We’re not just seeing prompt injection and misuse — we’re seeing attackers aim directly at the model itself.
Google says it has observed model extraction (distillation) attacks targeting Gemini at scale, with 100,000+ prompts used in some campaigns. According to eWeek’s reporting, Google attributes the activity to actors linked to countries including North Korea, Russia and China, and characterises it as intellectual property theft.
What is a model extraction (distillation) attack?
A model extraction attack is when an adversary uses legitimate access (for example, an API or a chatbot interface) to systematically query a model, collect outputs, and use them to train a cheaper “student” model that imitates the “teacher” model.
Google’s Threat Intelligence Group explains that this commonly uses knowledge distillation, a legitimate machine learning technique — but distilling from Gemini without permission violates Google’s terms of service and amounts to IP theft.
Why this matters (and who is actually at risk)
Google makes an important distinction: model extraction attacks don’t typically threaten the confidentiality, availability, or integrity of AI services for average users. The concentration of risk is on:
Model developers (loss of proprietary capability)
AI service providers (abuse that scales cost and erodes competitive advantage)
Organisations hosting custom models (competitors attempting to replicate domain-specific tuning)
In other words: it’s less like “someone hacked your inbox”, and more like “someone tried to copy your engine by test-driving it 100,000 times”.
What Google says attackers are trying to steal: reasoning traces
One of Google’s more specific examples is “reasoning trace coercion”.
GTIG says that while internal reasoning traces are normally summarised before being shown to users, attackers attempted to coerce Gemini into outputting fuller internal reasoning processes. In one campaign, GTIG reports:
Scale: 100,000+ prompts
Intent: replicate reasoning ability across a wide variety of tasks (including non‑English targets)
Outcome: Google says it recognised the attack in real time and reduced the risk of that campaign, protecting internal reasoning traces
This is a useful reminder for security leaders: “reasoning” isn’t just a UX feature — it can be a high-value signal for adversaries trying to distil model behaviour.
Mitigations that actually help
Because model extraction uses legitimate access patterns, classic perimeter controls don’t solve it on their own. The mitigations are operational and product-led:
1) Monitor access patterns for extraction behaviour
Google recommends that organisations offering AI models as a service monitor API access patterns that look like systematic probing or distillation attempts.
Practical signals include high-volume sampling across broad task coverage, unusual multilingual probing, repeated prompt templates, and automated query cadence.
2) Rate limiting and friction where it matters
Extraction is an economics game: attackers need volume. Controls that make high-volume probing expensive or noisy can materially reduce the viability of attacks.
3) Reduce learnable signal
If you expose richer internal traces, consistent formatting, or overly detailed explanations, you may increase the amount of “teacher signal” available to a distillation attacker. GTIG’s case study shows attackers explicitly target this.
4) Defensive responses to degrade student-model usefulness
Google notes it uses detection and mitigation techniques — including real-time proactive defences — to disrupt extraction attempts and reduce the value of the harvested outputs.
What this means for organisations using AI today
If you’re primarily an AI consumer (using Gemini, ChatGPT, Copilot, etc.), model extraction is not usually the most immediate risk. Your bigger day-to-day concerns are typically:
prompt injection / indirect injection via documents and web content
data governance and user permissions
connector/app access controls
If you publish or host models (including internal LLM apps), then extraction becomes a board-level topic: it is about protecting IP, controlling abuse costs, and ensuring your model can’t be cheaply replicated.
Summary
Google says Gemini has faced 100,000+ prompt campaigns aimed at model extraction/distillation, including attempts to coerce reasoning traces to accelerate “cloning”. The primary risk is to model developers and AI service providers, not typical end users — and the most effective mitigations are monitoring, rate controls, and product choices that limit learnable signal while disrupting high-volume abuse.
Next steps: Generation Digital can help you assess exposure across your AI stack — whether you’re consuming models (prompt injection and access controls) or operating them (abuse monitoring, rate limiting, and governance).
FAQs
Q1: What is a model extraction (distillation) attack?
A technique where an attacker uses legitimate access to systematically probe a model and use the outputs to train a cheaper “student” model that imitates the original. (cloud.google.com)
Q2: Did Google say Gemini was attacked at scale?
Yes. Google’s threat reporting and eWeek’s coverage describe campaigns involving 100,000+ prompts aimed at extracting Gemini capabilities. (eweek.com)
Q3: Are these attacks dangerous for normal Gemini users?
Google says model extraction attacks typically don’t threaten the confidentiality, availability, or integrity of AI services for average users; the risk is concentrated on model developers and service providers. (cloud.google.com)
Q4: What is “reasoning trace coercion”?
GTIG describes campaigns that attempt to force Gemini to output fuller internal reasoning traces, which could provide extra signal for distillation. Google says it detected and mitigated at least one such campaign in real time. (cloud.google.com)
Receive weekly AI news and advice straight to your inbox
By subscribing, you agree to allow Generation Digital to store and process your information according to our privacy policy. You can review the full policy at gend.co/privacy.



Generation
Digital

Canadian Office
33 Queen St,
Toronto
M5H 2N2
Canada
Canadian Office
1 University Ave,
Toronto,
ON M5J 1T1,
Canada
NAMER Office
77 Sands St,
Brooklyn,
NY 11201,
USA
Head Office
Charlemont St, Saint Kevin's, Dublin,
D02 VN88,
Ireland
Middle East Office
6994 Alsharq 3890,
An Narjis,
Riyadh 13343,
Saudi Arabia







Business Number: 256 9431 77 | Copyright 2026 | Terms and Conditions | Privacy Policy